Körbar referensmodell – öppen grund för fortsatt arbete
En öppen, körbar referensimplementation av AnomalyShield-metoden i Python. Den är framtagen för att myndigheter, forskare och ideella organisationer ska kunna läsa, köra, granska och bygga vidare på metoden – och för utvärdering av samarbetspartner. Ingen träningsdata, inga riktiga personuppgifter. Vikterna är illustrativa platshållare; en poäng är en risksignal för mänsklig granskning, aldrig ett skuldfastställande.
Demoresultat (syntetiskt, illustrativt)
Utdata från python examples/run_demo.py på en syntetisk population (120 000 entiteter, basfrekvens ~0,15 %). Diagrammen visar exakt det som metodrapporten beskriver – men nu som körbar kod: precisionen i toppen av kön med konfidensintervall, och kalibreringen efter temperature scaling.
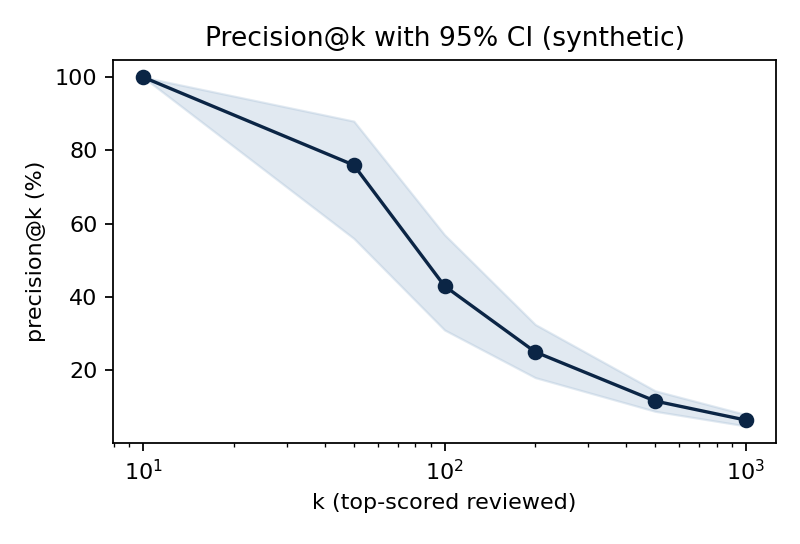
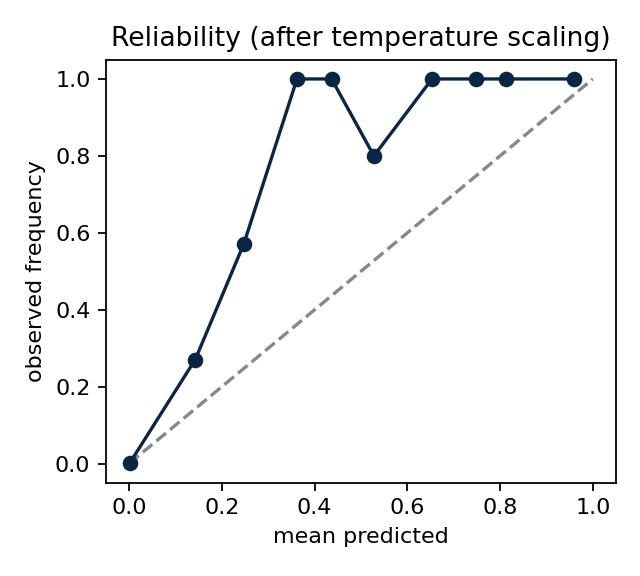
Innan någon verklig pilot krävs: märkt data, träning, kalibrering på uthållet data, rättvisegranskning, DPIA och rättslig grund (GDPR art. 8 och 22, DSA, EU:s AI-förordning) samt mänsklig granskning och lagliga eskaleringsvägar. Se MODEL CARD, GOVERNANCE och ACCEPTABLE USE.